Covid Deaths in U.S.: 1,107,794 Get Vaccinated!Stop the War in Ukraine!
Mark Twain once said, “I didn’t have time to write you a short letter, so I wrote you a long one.”
Several times over the last twenty years, I needed to write myself into existence. When I remember to start writing again, I find that I generate insights and connections that I otherwise missed. When I get the process moving, there is a natural flow to what and how I write.
I start out with free writing where I just let the random thoughts flow. Some of these thoughts are related to what I am working on or questions that colleagues have asked. I will select some of these thoughts to write a bit more formally in an email. For those emails that turn into a conversation, I will then generate an internal company blog post. As the ideas solidify through many conversations and white board sessions, I will then do an external blog post either to my personal or company blog. Depending on the reception and the conversations that the public post elicits, I will then generate a white paper.
At each stage of this process, I am more explicit about the organization of the content. Yet, the more important part of the evolution is becoming more conscious of the audience. The audience for my free writing is myself. The email audience is one or a couple of people. The internal company blog post is for my colleagues. The external posts are for a general audience which is often still vague. The white paper is for a specific external audience that I want to influence in some way. [NOTE: The TAI Group provides a methodology and coaching for how to identify and communicate with your target audience through their “Who’s There?” Platform.]
The evolution of the writing gets more explicit about the focus of the writing, the organization of the content, and the audience.
The content evolution in Knowledge Management (KM) systems follows a similar process. As you might imagine the real costs of a KM or a Personal Knowledge Management (PKM) system is the maintenance and evolution of the original thoughts and experiences.
What follows is the fourth stage of writing about my scattered thoughts on KM. These notes went from free writing to an email to an internal blog post to now a public (on my personal website) post.
In keeping with my personal WHY of creating order out of disorder, I am often asked by colleagues and folks that I mentor to provide a starting point for learning about a topic. Jason Velasco has asked me a couple of times to provide my thoughts on Knowledge Management in general and as a way to help his company with client consulting on KM. I’ve provided him with several articles and have described several times in Zoom meetings many of my thoughts (and rants) on KM. He asked me to take another shot at summarizing my thoughts.
In addition, one of the driving forces behind KnowNow is to create the best Personal Knowledge Management (PKM) system for knowledge workers.
I have shared many times that my basic problem with the term “knowledge management” is that it is a mis-categorization if you go to the definitions of what Knowledge is – biologically and philosophically.
On the philosophical side, I like Ackoff’s definitions which I have written about and even been quoted in Too Big to Know by David Weinberger (WUKID Extended ) [NOTE: This blog post references a previous post which has additional references and information] :
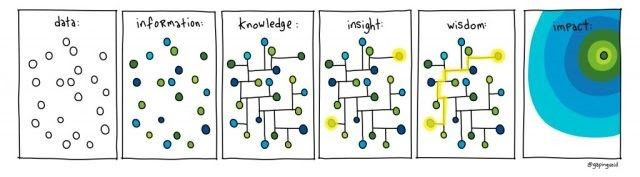
Since I met Russ Ackoff thirty years ago and learned about WUKID, I strive to advance from data to wisdom in my learning journeys. The journey to WUKID is a driver for my SoDoToTAO process. Russ gave me the practical definitions of the stages of learning:
Data – the raw stuff of the world. It could be a temperature reading 67 degrees or the price of a book or any of the raw things that we encounter each day.
Information – provides structure for data. A weather report puts the temperature (data) in context. The outside air temperature in Seattle, WA on July 10, 2007 was 67 degrees at 2 PM and the sun is shining. Each of the components of the previous sentence is data put together to form a glob of information.
Knowledge – is actionable information. Given the above weather information string I would know that it is going to be a nice day but cool for that time of year, so I would carry a light sweater or jacket if I were to go outside.
Understanding – is seeing patterns in knowledge and information. If the above weather string were combined with 20-30 days of similar strings of information and I had lived in Seattle for 10 or more years, I would be able to see a pattern of it being a cool summer. Understanding has a longer time component than information and knowledge. Understanding incorporates double loop learning as described in Schon’s The Reflective Practitioner.
Wisdom – is going beyond the levels of understanding to see larger scale systems and be able to predict behaviors and outcomes in the longer term future (5-15 years) based on seeing the patterns that arise through understanding. When lots of data over many years was refined into information, knowledge and understanding patterns, scientists were able to see long term weather patterns like el nino and la nina. Based on these patterns weather forecasters can predict longer term trends in Seattle and I can act accordingly.
I loved it when the Gapingvoid artists drew their image of WUKID and then added Impact:
What I love about these images from Gapingvoid is the text they provide to share the context behind the image:
“Semiotics is the study of the signs and symbols that imbue meaning and meaningful communication. It includes the study of signs and sign processes, indication, designation, likeness, analogy, allegory, metonymy, metaphor, symbolism, signification, and communication.
“Semiotics has been recognized as having important anthropological and sociological implications by many of the greatest innovators behind the respective disciplines. Umberto Eco proposed that every cultural phenomenon may be studied as communication; Clifford Geertz, arguably the 20th Century’s most respected anthropologist, once wrote that ‘culture is the culmination of symbols that transmit behavior’.
“It is with these thoughts in mind that Gapingvoid started to study how to impact organizational outcomes by informing culture, mindset, beliefs, and behaviors through semiotic tools.
“We have consistently witnessed and measured how people’s perceptions can be shifted through meaning attached to objects. Back in 2005, we popularized the term ‘social object’ with semiotics in mind: the idea that objects spread ideas faster and more effectively than nearly any other medium We see daily examples in internet memes and Red Baseball Caps, which have come to represent an entire political ideology.”
What I like about the cartoon is adding the “so what” piece to WUIKID – so what does KM do to create an impact? Their cartoon illuminates outcome based thinking as well.
On the biology side we have the work of Orna and Lakoff and Johnson. These authors look at how external information crosses the barrier to become a part of our biology.
Elizabeth Orna in Making Knowledge Visible: Communicating Knowledge Through Information Productsdescribes the process whereby information is transformed into knowledge and vice versa. She claims that information lives in the outside where it becomes visible and available to others and be able to feed their knowledge. But knowledge is not something that I can give to someone else, because information has to be transformed into something that lives only in a human mind. We are constantly and generally invisibly transforming information into knowledge and back into information for others to consume.
Lakoff and Johnson in Metaphors We Live By and Philosophy in the Flesh go further in their distinctions between information and knowledge claiming that knowledge only results when we have a physical body that can sense and act in the world.
Orna’s image of the cycle between information and knowledge (see below) – information is outside the skin of an individual and knowledge resides inside the skin.
If you pay attention to these biological definitions, then the key bit that is missing for a computer to be able to have knowledge reside within is to combine the advances in AI and ML with effectors and affectors (the robotics and IoT world). We are getting much closer with these technologies but the key bit is that the computer has to be able to have the equivalent of our five senses (sight, smell, touch, hear, taste) AND be able to then operate on the world (affecters) to be able to interact with another human’s five senses.
We are getting close with all of the advances in AI/ML and robotics and very human complex things like driving a car. But we are not there yet. The conversational advances with tools like Alexa and ChatGPT are another key along with explainable AI and ML.
“Explainable artificial intelligence (XAI) is a set of processes and methods that allows human users to comprehend and trust the results and output created by machine learning algorithms. Explainable AI is used to describe an AI model, its expected impact and potential biases. It helps characterize model accuracy, fairness, transparency and outcomes in AI-powered decision making. Explainable AI is crucial for an organization in building trust and confidence when putting AI models into production. AI explainability also helps an organization adopt a responsible approach to AI development.”
“The relative ease of fooling these neural networks is worrying. Beyond this lies a more systemic problem: trusting a neural network.
The best example of this is in the medical domain. Say you are building a neural network (or any black-box model) to help predict heart disease given a patient’s records.
When you train and test your model, you get a good accuracy and a convincing positive predictive value. You bring it to a clinician and they agree it seems to be a powerful model.
But they will be hesitant to use it because you (or the model) cannot answer the simple question: “Why did you predict this person as more likely to develop heart disease?”
This lack of transparency is a problem for the clinician who wants to understand the way the model works to help them improve their service. It is also a problem for the patient who wants a concrete reason for this prediction.
Ethically, is it right to tell a patient that they have a higher probability of a disease if your only reasoning is that “the black-box told me so”? Health care is as much about science as it is about empathy for the patient.”
From a definitional stage, my assertion is that machines are still not capable of creating, storing or producing knowledge – yet. We are getting close, but not there yet. Yet, the field of Knowledge Management has been around for at least 40 years. So what are they talking about. My assertion is that we are still talking about Information Management, not Knowledge Management. Through things like the web, Google search, and Youtube an incredible amount of KNOW HOW is able to be shared. But the user still has to verify it and test it and internalize it for that information that is on the web to become knowledge and their own Know How internal to the human.
The classic one-line definition of Knowledge Management was offered up by Tom Davenport early on (Davenport, 1994): “Knowledge Management is the process of capturing, distributing, and effectively using knowledge.” Probably no better or more succinct single-line definition has appeared since.
A new definition of KM
A few years after the Davenport definition, the Gartner Group created another definition of KM, which has become the most frequently cited one (Duhon, 1998), and it is given below:
“Knowledge management is a discipline that promotes an integrated approach to identifying, capturing, evaluating, retrieving, and sharing all of an enterprise’s information assets. These assets may include databases, documents, policies, procedures, and previously un-captured expertise and experience in individual workers.”
The one real lacuna of this definition is that it, too, is specifically limited to an organization’s own information and knowledge assets. KM as conceived now, and this expansion arrived early on, includes relevant information assets from wherever relevant. Note, however, the breadth implied for KM by calling it a “discipline.”
Both definitions share a very organizational and corporate orientation. KM, historically at least, was primarily about managing the knowledge of and in organizations. Rather quickly, however, the concept of KM became much broader than that.
A graphic map of Knowledge Management
What is still probably the best graphic to try to set forth what constitutes KM, is the graphic developed by IBM for the use of their own KM consultants. It is based upon the distinction between collecting stuff (content) and connecting people.
I like the notion of the 4Hs:
Harvest
Harness
Hunting
Hypothesize
Or translated into more IT Terms:
Content Management
Expertise Location
Lessons Learned
Communities of Practice
I like the stages of evolution of KM within an organization:
Stage 1 of KM: Information Technology
Stage 2 of KM: HR and Corporate Culture
Stage 3 of KM: Taxonomy and Content Management
At least in this article they recognize several issues:
Tacit knowledge (what is in the individual)
Knowledge Retention and Retirees (I would also add onboarding)
Scope of KM has greatly increased
What I like about this article is that it captures the range of what is talked about as KM. Although in my estimation we are still talking about Information Management.
Challenges with implementing KM
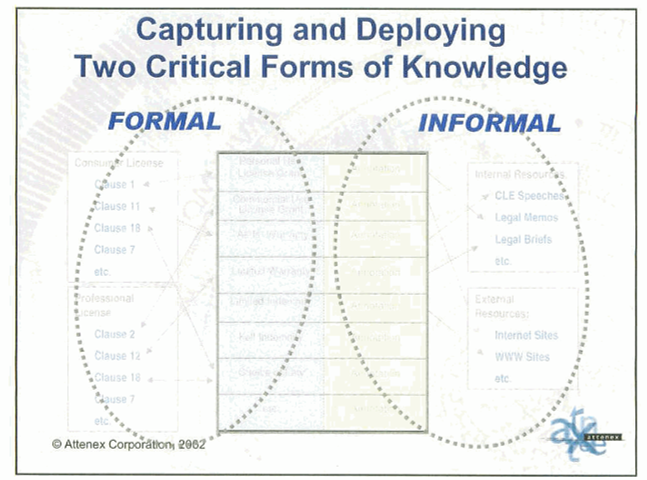
A couple of examples of KM systems that I’ve built or managed are Attenex Structure and Conga’s Contract Lifecycle Management system.
The purpose of Attenex Structure was to provide a clause database for transactional attorneys so that they could quickly construct transactional documents like NDAs or software licenses from the best practices of a law firm or a corporation (Microsoft, 3M, Fair Isaac). The system was a KM system that had all of the components of the 4Hs and the equivalent of my presentation on CLM.
Even though CLM is a specific form of KM, I hope that you can see the relationships with the more general article on KM and the 4Hs along with their stages of implementation.
What is not obvious in looking at these definitions, capability maturity models and stages of evolution is some of the challenges that are faced.
Challenges to Creating Knowledge Management Systems
The following is a partial list of the challenges we faced in both developing and implementing these systems. I will use the 4Hs as a framework for cataloging some of the challenges:
Harvest
This is probably the single biggest challenge for an existing organization. There are already terabytes of information that need to be sifted through to find examples of knowledge.
One of the many reasons I selected both Structure and Patterns at Attenex is that I thought Patterns would be a great way to Harvest the information from an existing organization’s mountains of contracts. It is also why I proposed to Conga that they buy Ringtail to easily do this Harvest step.
Without an eDiscovery like enterprise search capability the very first step fails. Advanced eDiscovery (E5 MSFT 365 license) and KnowNow can relatively easily do this step today.
Which then leads to the second big challenge which is the existing examples are all specific to a particular need. They are not general nuggets of knowledge. They are only a specific instance.
If we take MSFT or Amazon AWS as an example, they each have 100s of thousands of examples of proposed and negotiated software licenses. But they are all specific.
To turn the specific examples into general templates takes 100s to 1000s of hours of your highest caliber legal talent to find the general cases of terms (need agreed to definitions of the legal phrases – not an easy process with a group of lawyers), sentences, clauses and legal form collections of clauses. Then you have to assume that many of the clauses will want to be negotiated by the other party. So these clauses have to have pre-defined fallback clauses in case the other party pushes back. And on and on in an infinite regression to get to shared content that the rest of your organization will actually use.
Which then leads to the third challenge – users and lawyers are still going to want to customize the standard content or clauses. So a part of the harvesting process is to create knowledge that can be used as a starting point AND then capture how AND WHY that content was changed for a specific need. Then this content has to be recycled – the actual change and the reason why – back to the Content Keepers to decide whether to update the knowledge base nuggets. This process is not unlike the two pieces of Wikipedia – what the user sees and then the edit and discussion history behind all changes to an existing page. Example: Ackoff Wikipedia Page and Ackoff Page View History.
Harness
The assumption that many developers of KM systems have is that once the knowledge is harvested then it is a good way to find the people that are knowledgeable about a given topic.
The first challenge with Harnessing is to keep not just the knowledge examples that were found in the harvesting, but also the people that created the knowledge nuggets in the first place along with their imprimatur. When I access a clause from the databank, I will want to know if it was created by a senior partner in that specific practice (IP, Litigation, Trust and Wills, Patents ….) or whether it was generated from an associate. Further, I would like to know if that clause has been used in any specific contracts and then be able to look at the full contracts to see the context of the clause usage. This need leads to many challenges like are their ethical walls and does the person trying to use the information have the permissions to look at given client examples. Just keeping the ethical walls and client access up to date is a huge challenge in and of itself.
The second challenge is that at some point you need to be able to capture the expertise of the person that created the knowledge nugget. Whether that is from a resume or an internal bio, those resumes are often inflated. More junior people typically claim that they are competent in every aspect of the law. What you really want to know is not whether the knowledge creator claims that they are an expert, but you want to find some evidence of their claimed expertise. Which leads us back to the Harvesting challenges, not only do you want to find examples but you want to find out how many examples per person in your enterprise were found. This is similar to trying to judge the expertise of a medical provider. Each time I have had a surgery I desperately want to know how many times has this particular surgeon performed this operation, on what types of people (my sex and age), and what were the outcomes. As it turns out this information is actually available (through Medicare and Medicaid reports), it just isn’t available to me as a health care consumer.
The third challenge is can I actually access the expertise of the person I seek. Is the person available and accessible? How much will it cost? How will the provider of the knowledge be compensated?
The fourth challenge is what kind of knowledge am I really looking for? Am I an expert and I just need the specific text of a clause? Or am I a novice and I actually need many hours of tutelage and consultation – that is, I am actually looking for training or mentoring?
The fifth challenge is does the person who is being sought out for knowledge keep a record of their requests to that they can feed that back into the system to create a demand for formalizing additional topics and nuggets into the knowledge base?
Hunting
Most KM systems are built to retrieve specific things. Wikipedia is a good example. I am searching for something and a wikipedia entry shows up and I usually will go to it to get a starting point. But I would never think of browsing Wikipedia – there is just too much stuff. Similarly with Amazon, I go there to look for specific books and I love some of the recommendations, but even after 27 years, Amazon is not a replacement for browsing in a library. In a library I can go to the section of books that is close to what I am interested in and then browser for interesting titles.
The first challenge is how do you make it easy to browse?
The second challenge is how do you provide serendipity without angering the user. Sean McNee in his PhD dissertation on recommender systems for computer science articles studied the art of list making when returning search results to the user. What he found is that the first 2-3 results had to be items that the user KNEW would be directly relevant to their search request. This was the user’s way of “trusting’ the recommended results. Then about the third entry the recommender system could insert something that was relatively novel or serendipitous to the search request. Depending on the particular search system, it would track whether the user only selected those items that directly met the search results or the serendipitous ones. If serendipitous, then the system could put a few more into the next requests.
The third challenge stems from how to help the user think outside the box through “oblique knowledge.” This article by Phillipe Baumard provides a philosophical discussion of the types of knowledge.
The fourth challenge comes back to the reward system for pursuing serendipity. For a period of time DuPont in conjunction with Charley Krone’s consulting changed their compensation system to reward executives and managers for pursuing activities that were learning activities rather than just repeating tried and true practices. The reward was for the pursuit, not whether it actually resulted in an innovation. Google is relatively famous for the 20% time at discretion of the employee. The key part of this challenge is how does this learning make ita way back into the knowledge base. It is hard enough to get people to writeup their successes. It is impossible to get people to writeup their failures. This failure of results was one of the goals for the scientific Journal of Irreproducible Results. It is also the intent behind creating systems to track and analyze lost order reports.
Hypothesize
Over the years many attempts were made to create “spaces” for creating new things. The Chautaqua Groups were attempts to bring people together starting in the 1800s. Large events like CES are attempts at bringing a whole industry together to create places to understand where an industry is today along with seminars for where the industry is going in the next couple of years. LegalTech is a small example of this. With the advent of Covid, these shows have had to move virtually. The hardest thing for these new virtual show systems to deal with is the networking component (both formal and informal) of a trade show.
The first challenge is just to get the right people into a space.
The second challenge is to record the conversations so that they can become early warning systems of trends.
The third challenge is to capture who is meeting with whom and construct the social networks that matter.
The fourth challenge is separating out what is immediately useful from what is useless to what might be useful in the future.
The fifth and perhaps biggest challenge is how do the attendees bring back their experience of the industry “knowledge space” to their colleagues.
Late Breaking News
Last week OpenAI announced the availability of ChatGPT. I suspect that 1000s of person hours were lost this week exploring this very engaging technology. One of the potential uses of ChatGPT is to replace Google search. Instead of your search requests generating 1000s of URLs to have to wade through, ChatGPT provides a narrative summary of the information:
“In layperson’s terms, ChatGPT is a lot more human than prior search engines, albeit with a supercomputer’s wealth of data — think Scarlett Johansson in “Her.” For instance, users who Google “what is the maximum dosage of vitamin D per day” simply received a link to HeathLine.com. However, when they posed the same question to the AI, it formulated an in-depth dissertation, the Times of London reported.”
I asked ChatGpt to define “knowledge management”:
“Knowledge management is the process of creating, sharing, using and managing the knowledge and information of an organization. It involves identifying, capturing, evaluating, and distributing the knowledge and information that is generated within an organization, as well as incorporating external sources of information. The goal of knowledge management is to enhance an organization’s ability to learn, innovate, and adapt to change. This can be achieved through various means, such as creating a knowledge-sharing culture, implementing knowledge management systems and technologies, and encouraging collaboration and communication within the organization.”
Asking ChatGPT was a lot easier than writing this blog post. I ask my audience which is more useful.
Summary
I don’t see any evidence that those systems that purport to be about Knowledge Management are actually dealing with knowledge. I assert that they are still Information Management Systems.
Most of the activity I see that purports to be about KM only deals with the Harvest Quadrant. As Greg Buckles pointed out there are many software systems that have been developed for the other quadrants but they don’t seem to be successful (particularly the expertise location).
KnowNow has aspirations to be a platform that can support all of the 4Hs. But right now we are mostly in the Harvest quadrant. Assuming we are successful I am very interested in using XR (VR and AR) to go after both tacit knowledge and the other three quadrants (Harness, Hunting, and Hypothesize).
Retired software executive, ardent book reader. Enjoying slow travel, learning to cook, and searching for fine wine growing. Grandfather, husband, father, brother. Recorder of Seattle sunrises. Voting blue.💙