
Day 291 of Self Quarantine Covid 19 Deaths in U.S.: 333,000 GA Vote!!
I am in the process of writing my second book – Know Now. I had planned for this to be a traditional book aimed at early stage entrepreneurs and product managers in startups and large companies. As I was getting ready to write, Rowan Cockett of iooxa introduced me to the work he is doing to put a more friendly user interface on top of Jupyter Notebooks.
“What is a Jupyter notebook?” I asked. He shared that it is what research and data scientists are using to intertwingle narrative and computing. I realized that this kind of platform was what I’ve been looking for, but thought I was going to have to use a combination of text and then some auxiliary spreadsheets. Yet, the more that I dug into Jupyter notebooks I realized how much computing and use of a dogs breakfast of spread sheets that a startup CEO and a product manager are always creating. The spread sheets are mostly for themselves to keep track of the 100s of things that need a little bit of data and arithmetic. A Juptyer notebook is a great way to combine both.
The challenge though is there aren’t that many of us that are comfortable programming or know the Python language that is used in Jupyter notebooks. I could always cajole one of my software engineering colleagues into helping me out or I could reteach myself how to program.
About this time, GPT-3 was announced. I followed OpenAI and their previous announcements, but not very closely. The GPT-3 announcement was stunning to me for one big reason – the initial demos showed that GPT-3 could also do some programming. The early examples showed the user typing a few English language sentences and then GPT-3 would generate the program. The “no code” movement just took a huge leap forward. KDnuggets shared a diagram of the growth in parameters that OpenAI used to go from GPT-2 to GPT-3.

Sharif Shameem showed an early demo of the “no code” in his tool debuild.co which builds a functioning React app by describing what he wants to do in English.

By typing in the English of what he wants:
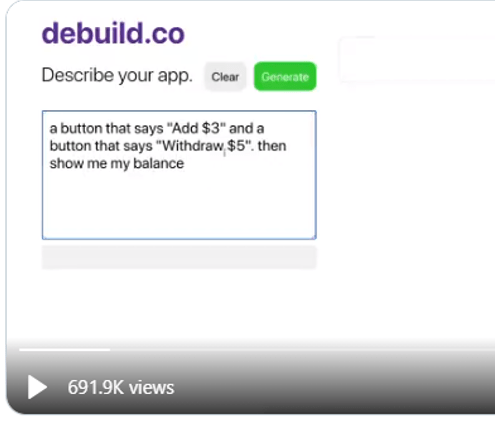
You can see that GPT-3 adds the two buttons and then executes the buttons.
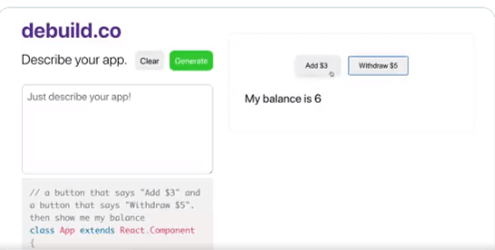
The program that GPT-3 generates is below the text box that the user enters their English language description of the program.
After this jaw dropper of a capability, I searched for every example I could find from the developers who got early access to the GPT-3 beta.
Then, Microsoft announced their first product that arose from Project Cortex – Sharepoint Syntex. The Syntex demo illustrates how a normal Microsoft 365 user could create a sophisticated document recognition system and extract key features from the document with just a couple of example documents. The demo replicated what we spent $15 million to try and do at Conga just a year earlier. Now the contract recognition and field extraction could be done by a normal user in just a few minutes for the price of an Office 365 license.
I reached out to my colleague John Conwell, a data scientist at Domain Tools, to see how he used Jupyter notebooks. He showed me how easy it is to do the coding, generate tables of results or output the results in to a data file. Then he showed me how he does natural language processing and then cluster mapping of the themes in his unstructured text. He demoed how Jupyter, Python and all the many open source libraries could almost replicate what we did in Attenex Patterns.
As I thought more about the Know Now book I am drafting, I realized that I would have a lot of text. Some of the text would be mine, some of the text would be from searchable PDFs of the 2500 books I want to reference, and some would be from the 1000s of web pages I’ve curated and captured within Evernote. I envisioned a search engine being needed to navigate the Know Now book as it was unlikely to ever be read linearly. I needed a Personal Patterns inside of my Know Now book.
As I absorbed the implications of what I wanted to write, the audience I am writing for, and the new technologies like Jupyter, GPT-3, and Project Cortex, I thought that GPT-3 could “write” both the narrative and the code for a given topic. All I had to do was to generate a couple lines of English or point to some source text and GPT-3 could generate both the narrative and the computing cells to accomplish the task.
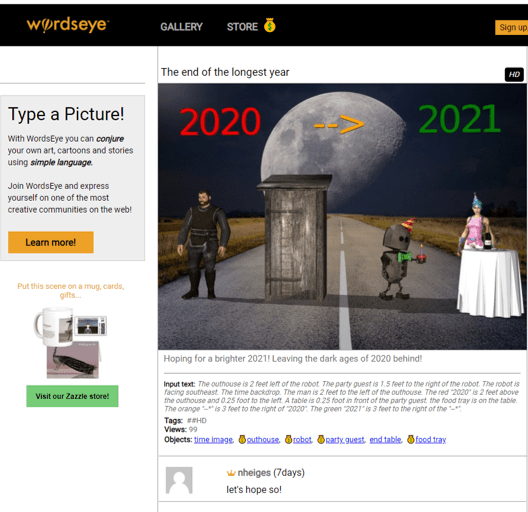
For years I’ve followed the WordsEye tool where you can “type a picture.”
The input text that generates this image is:
“The outhouse is 2 feet left of the robot. The party guest is 1.5 feet to the right of the robot. The robot is facing southeast. The time backdrop. The man is 2 feet to the left of the outhouse. The red “2020” is 2 feet above the outhouse and 0.25 foot to the left. A table is 0.25 foot in front of the party guest. the food tray is on the table. The orange “–*” is 3 feet to the right of “2020”. The green “2021” is 3 feet to the right of the “–*”.”
I remembered a demo in the past from Marklogic (an XML database company) who partnered with Reed Elsevier (now RELX Group) to generate custom documents on the fly from the large database of text books that Elsevier had in XML format (see case study on Unlocking the Value of Content at Elsevier). In the medical example, you would ask a question within a MarkLogic application and it would go retrieve that information from the text books and then generate a 3-5 page great looking pamphlet on the topic – either online or in print. Since Elsevier had put all of the formatting along with the XML in their text book the output of a query looked like it had retrieved a “published” result. Yet, the answer and the output occurred in real time. Elsevier found another revenue stream for the high cost content that went into their textbooks.
With GPT-3, maybe I can do the same thing AND generate the coding cells to go along with the narrative. As an example of a blog post that contains both narrative and some rudimentary formulas, Paul Graham talked about a formula in The Equity Equation for how to allocate stock to the first 10-20 employees of a startup.
“An investor wants to give you money for a certain percentage of your startup. Should you take it? You’re about to hire your first employee. How much stock should you give him?
These are some of the hardest questions founders face. And yet both have the same answer:
1/(1 – n)
Whenever you’re trading stock in your company for anything, whether it’s money or an employee or a deal with another company, the test for whether to do it is the same. You should give up n% of your company if what you trade it for improves your average outcome enough that the (100 – n)% you have left is worth more than the whole company was before.
For example, if an investor wants to buy half your company, how much does that investment have to improve your average outcome for you to break even? Obviously it has to double: if you trade half your company for something that more than doubles the company’s average outcome, you’re net ahead. You have half as big a share of something worth more than twice as much.
In the general case, if n is the fraction of the company you’re giving up, the deal is a good one if it makes the company worth more than 1/(1 – n).”
As you start to work out the arithmetic, it becomes pretty clear that you need a spread sheet or maybe even a program. As you look at the article some more, you realize that Graham is really describing a planning tool and a simulation tool where you want to think through what kinds of employees you need and how much value each will bring to the new entity. This tool needs to be cumulative so that you have the plans from previous hires as the starting point for the next hire.
To test out what the compute cells might look like to accompany the article, I had an intern use Google Colab (a Jupyter notebook alternative) to test these ideas out. In the narrative cells, we placed Graham’s article. In the compute cells, we used his formula as a starting point, but quickly realized we needed to generate our own formulas to guestimate some of the variables that Graham describes like the pre-money valuation of your startup.

Letting my imagination run wild, I wonder if I can “connect” the Know Now book to the reader’s email and then suggest that they check the explanatory information in the book to help them think through an upcoming action. With the above example in mind, Know Now could figure out that the CEO is using job boards to post an opening in their startup or asking former colleagues for recommendations for a particular set of job skills. Or I might see that the CEO is setting up some interviews with prospective hires. I could send an alert through email or Slack or Microsoft Teams to say “It looks like you are getting ready to hire somebody. Have your thought about the compensation package you are going to offer? If not, you might want to check out Paul Graham’s article and then the compensation simulation tool that goes with it.”
With Graham’s article as a starting point, GPT-3 could then customize the article in the context of the current CEO, their company, the nature of their business, and then start filling in some of the variables in the compute cells of the Jupyter notebook.
The task of authoring the Know Now book becomes more of a curation process rather than a complete authoring process. The curation process combines the following:
-
- Knowing what topics are important for the target audience – in my case the early stage startup CEO or product manager
- Finding the best content which can serve as source material or augmenting material for the GPT-3 knowledge base
- Knowing what to look for in the stream of communications (email, Slack, Teams) for the CEO or Product Manager
- Connecting the topics and content to the need of the CEO or product manager by seeing GPT-3 with the topic
What I like about these ideas and the capabilities of GPT-3, Jupyter notebooks, and Project Cortex is that they can be easily connected through a platform like Microsoft 365 where I spend most of my day. As an author, I like the ability to mass personalize the content that I am creating and that a wealth of others have created to the day to day work of an early stage startup CEO.
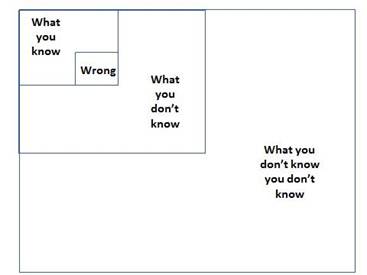
So much of the work of a new CEO in a new startup is figuring out what you don’t know you don’t know (see the Four Boxes of Knowing) and then being able to quickly learn what you need Just In Time. So much of entreprenuerial literature is Just in Case learning rather than Just in Time. The combination of these new technologies and appropriate personalized content promises an exciting shift to Just In Time learning while you are doing the work of your startup business.
If you want to learn a bit more with a curated demo of several of GPT-3’s test applications, this video provides a wide ranging overview of what is possible.
